2026
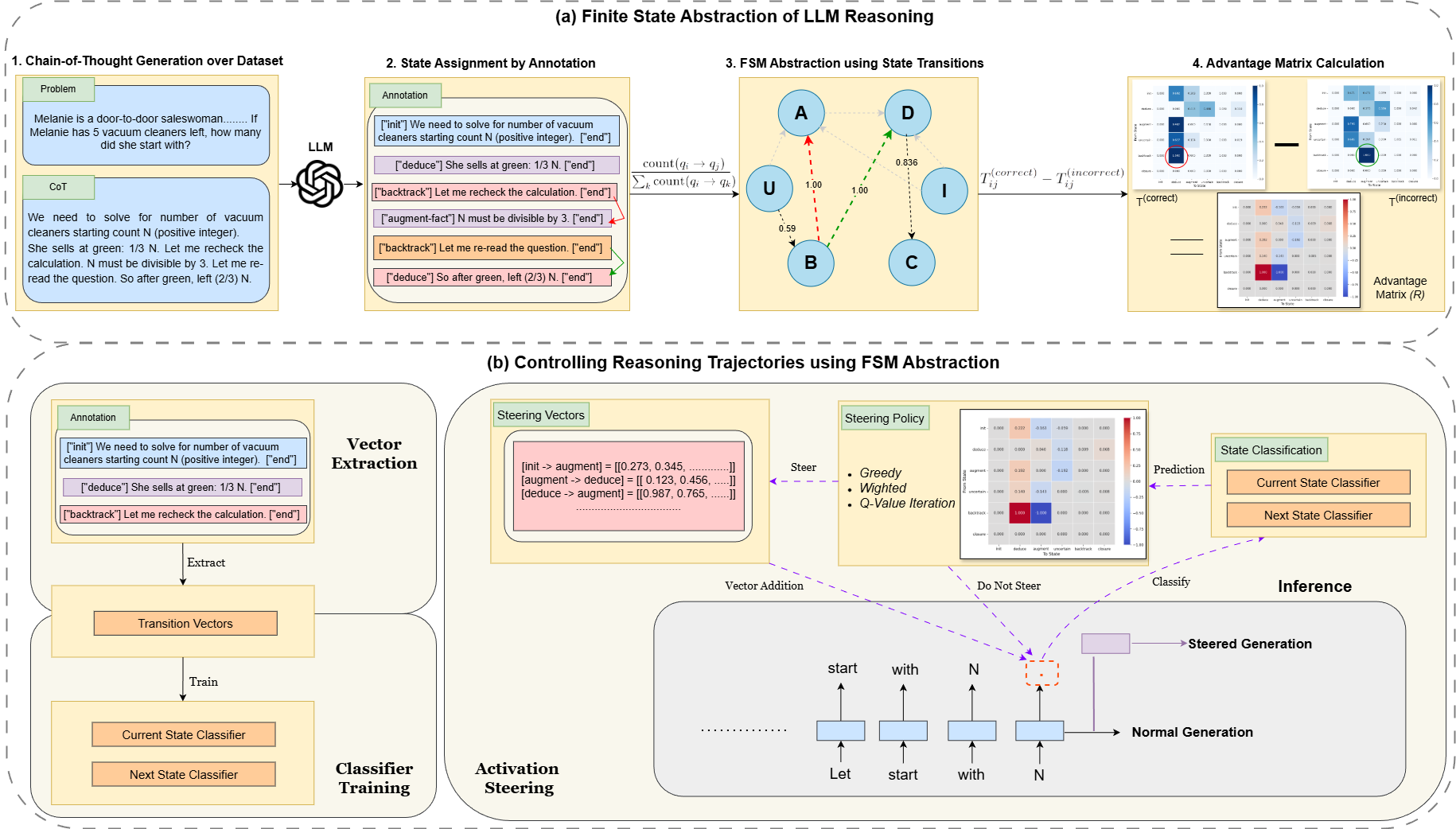
Modeling Hierarchical Thinking in Large Reasoning Models
G M Shahariar*; Erfan Shayegani*; Ali Nazari; Nael Abu-Ghazaleh. (* equal contribution )
ICML 2026 Oral
TL;DR: We model and steer LLM reasoning as outcome-aligned trajectories over FSM states, enabling sentence-level inference time control via latent interventions.
# LLM reasoning # chain-of-thought # FSM # mechanistic interpretability # activation steering

PII-VisBench: Evaluating Personally Identifiable Information Safety in Vision Language Models Along a Continuum of Visibility
G M Shahariar; Zabir Al Nazi; Md Olid Hasan Bhuiyan; Zhouxing Shi.
ACL Findings 2026
TL;DR: We show that Vision Language Models leak more personal information about people with greater online visibility, introducing a benchmark that reveals visibility-dependent privacy failures.
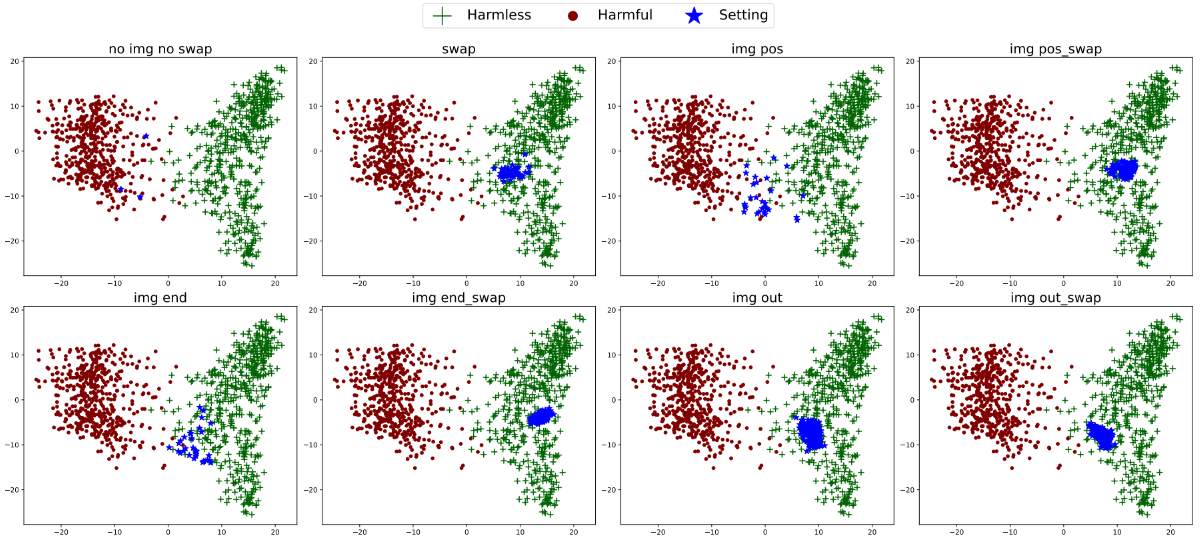
Misaligned Roles, Misplaced Images: Structural Input Perturbations Expose Multimodal Alignment Blind Spots
Erfan Shayegani*; G M Shahariar*; Sara Abdali; Lei Yu; Nael Abu-Ghazaleh; Yue Dong. (* equal contribution )
ICLR 2026 Poster
TL;DR: We model and steer LLM reasoning as outcome-aligned trajectories over FSM states, enabling sentence-level inference time control via latent interventions.

Are Vision Language Models Cross-Cultural Theory of Mind Reasoners?
Zabir Al Nazi; G M Shahariar; Md. Abrar Hossain; Wei Peng.
ACL C3NLP Workshop 2026
TL;DR: We introduce CulturalToM-VQA to probe Theory of Mind in diverse cultural contexts, revealing that frontier VLMs exhibit an "illusion of empathy" driven by social desirability bias and safety alignment artifacts rather than robust social reasoning.

2025
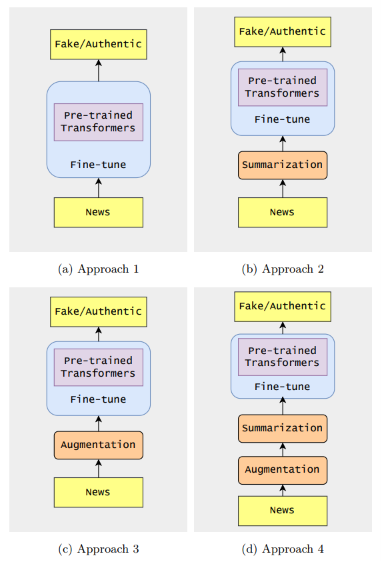
Tackling Fake News in Bengali: Unraveling the Impact of Summarization vs. Augmentation on Pre-trained Language Models
Arman Sakif Chowdhury*; G M Shahariar*; Ahammed Tarik Aziz; Syed Mohibul Alam; Md. Azad Sheikh; Tanveer Ahmed Belal. (* equal contribution )
SN Computer Science 2025
TL;DR: We propose a novel methodology consisting of four distinct approaches using summarization and augmentation to detect Bengali fake news.

Evaluating the Reliability of CNN Models on Classifying Traffic and Road Signs using LIME
Md. Atiqur Rahman; Ahmed Saad Tanim; Sanjid Islam; Fahim Pranto; G M Shahariar; Md. Tanvir Rouf Shawon.
Intelligent Networks and Systems 2025
TL;DR: We focus on the evaluation of the Convolutional Neural Network (CNN) models’ reliability in the identification of traffic and road signs.
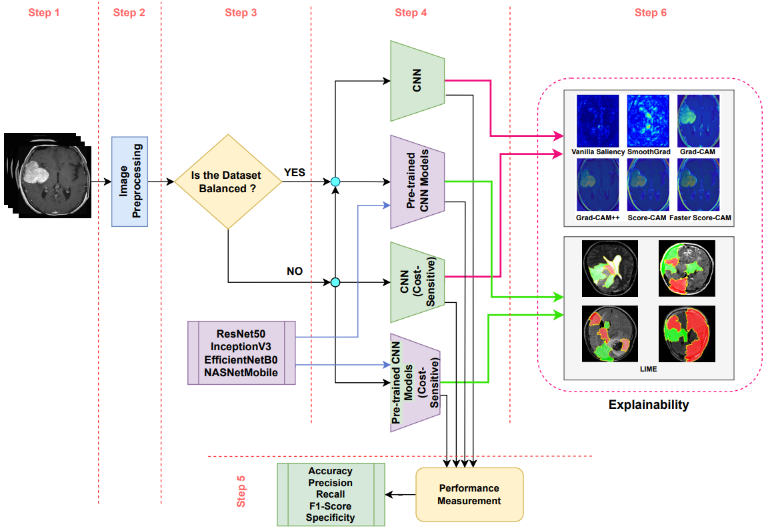
Explainable cost-sensitive deep neural networks for brain tumor detection from brain MRI images considering data imbalance
Md Tanvir Rouf Shawon*; G M Shahariar*; Farzad Ahmed*; Sajib Kumar Saha Joy*. (* equal contribution )
Multimedia Tools and Applications 2025
TL;DR: We employ the concept of a cost-sensitive neural network for an imbalanced dataset and compared the performance of a standard convolutional neural network (CNN) and four pre-trained CNN models.
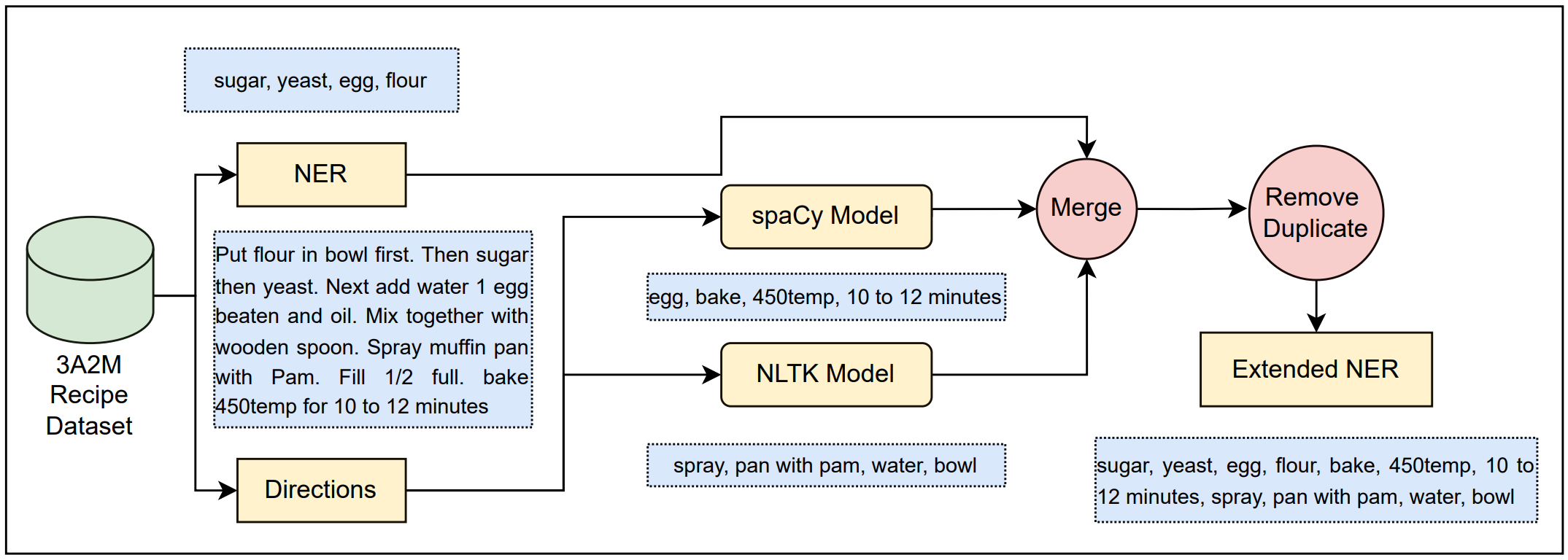
Towards Automated Recipe Genre Classification using Semi-Supervised Learning
Nazmus Sakib*; G M Shahariar*; Md. Mohsinul Kabir; Md. Kamrul Hasan; Hasan Mahmud. (* equal contribution )
PloS one 2025
TL;DR: We create a pipeline that generated a vast annotated dataset consisting of two million culinary recipes with extended named entities extracted from recipe descriptions.
2024

Adversarial Attacks on Parts of Speech: An Empirical Study in Text-to-Image Generation
G M Shahariar; Jia Chen; Jiachen Li; Yue Dong.
EMNLP Findings 2024
TL;DR: We investigate the impact of adversarial attacks on different POS tags within text prompts on the images generated by T2I models.
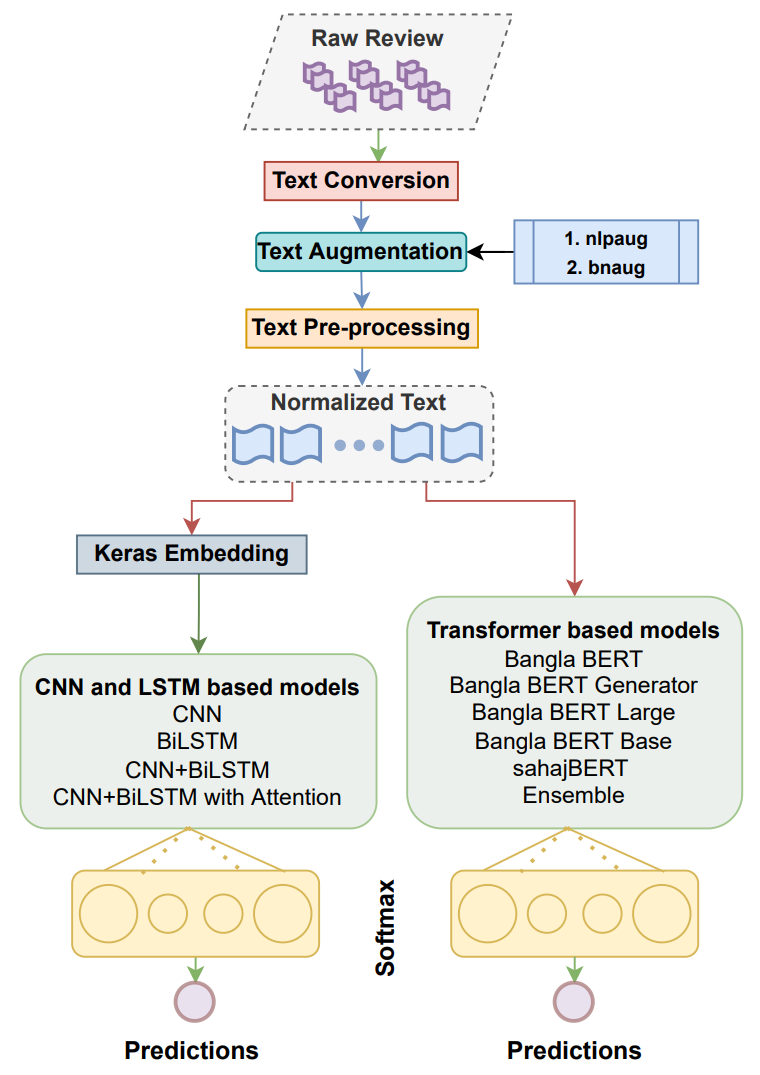
Bengali Fake Reviews: A Benchmark Dataset and Detection System
G M Shahariar*; Md. Tanvir Rouf Shawon*; Faisal Muhammad Shah; Mohammad Shafiul Alam; Md. Shahriar Mahbub. (* equal contribution )
Neurocomputing 2024
TL;DR: We introduce the Bengali Fake Review Detection (BFRD) dataset that focuses on food-related reviews in Bengali language.

Mitigating Extrinsic Gender Bias for Bangla Classification Tasks
Sajib Kumar Saha Joy*; Arman Hassan Mahy*; Meherin Sultana; Azizah Mamun Abha; MD Piyal Ahmmed; Yue Dong; G M Shahariar. (* equal contribution )
Arxiv 2024
TL;DR: We propose RandSymKL, a randomized debiasing strategy integrated with symmetric KL divergence and cross-entropy loss to mitigate the bias across task-specific Bangla pretrained models.
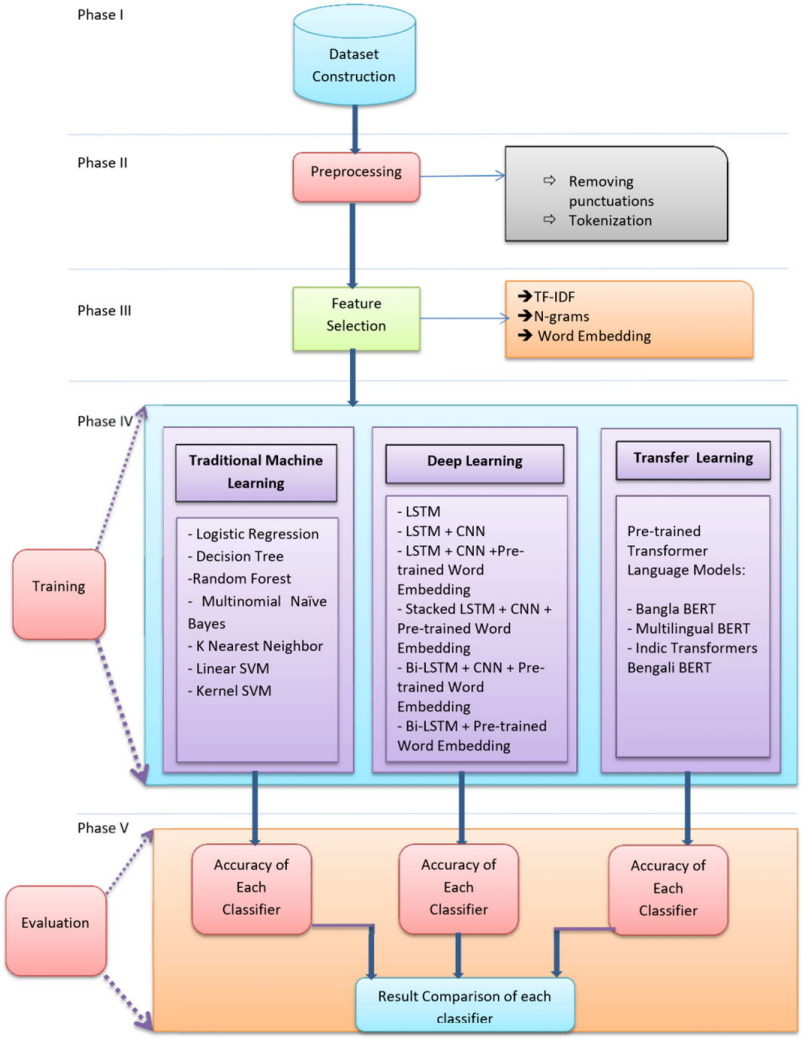
Ben-Sarc: A self-annotated corpus for sarcasm detection from Bengali social media comments and its baseline evaluation
Sanzana Karim Lora; G M Shahariar; Tamanna Nazmin; Noor Nafeur Rahman; Rafsan Rahman; Miyad Bhuiyan; Faisal Muhammad Shah.
Natural Language Processing 2024
TL;DR: We develop a large-scale self-annotated Bengali corpus for sarcasm detection.
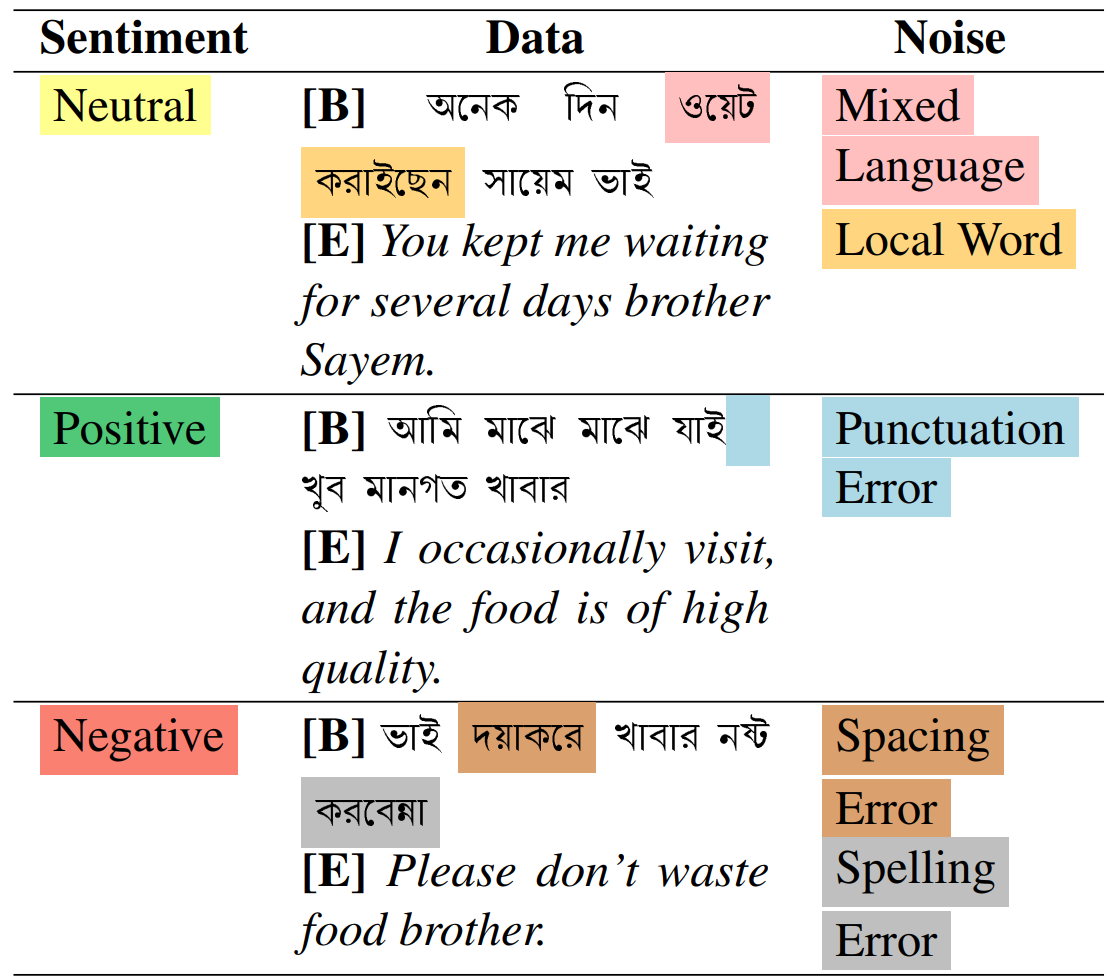
A Comparative Analysis of Noise Reduction Methods in Sentiment Analysis on Noisy Bangla Texts
Kazi Toufique Elahi; Tasnuva Binte Rahman; Shakil Shahriar; Samir Sarker; Md. Tanvir Rouf Shawon; G M Shahariar.
W-NUT, EACL 2024
TL;DR: We employ machine learning, deep learning and fine-tune pre-trained transformer models to identify noise types in noisy Bangla texts (a multi-label classification task) and to perform sentiment analysis on both noisy and noise-reduced texts (a multi-class classification task).
2023
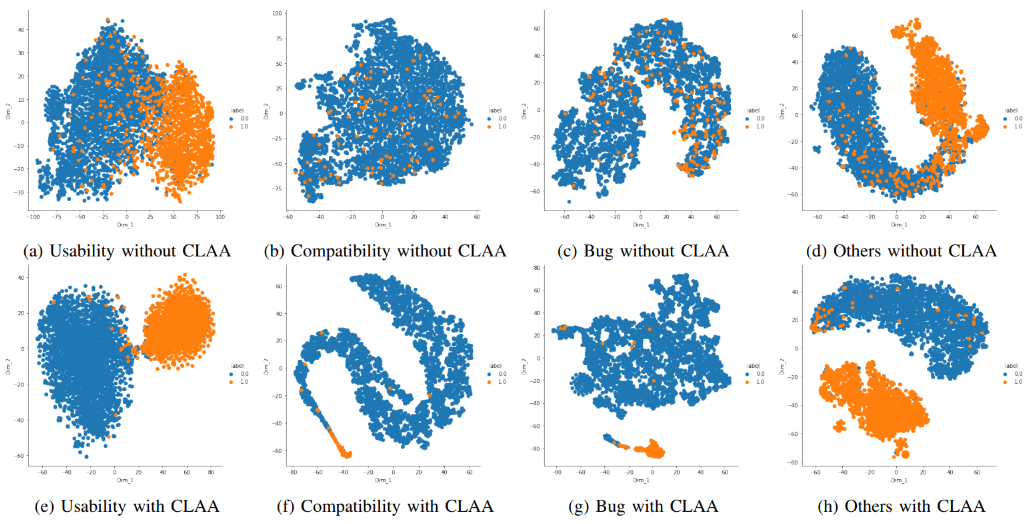
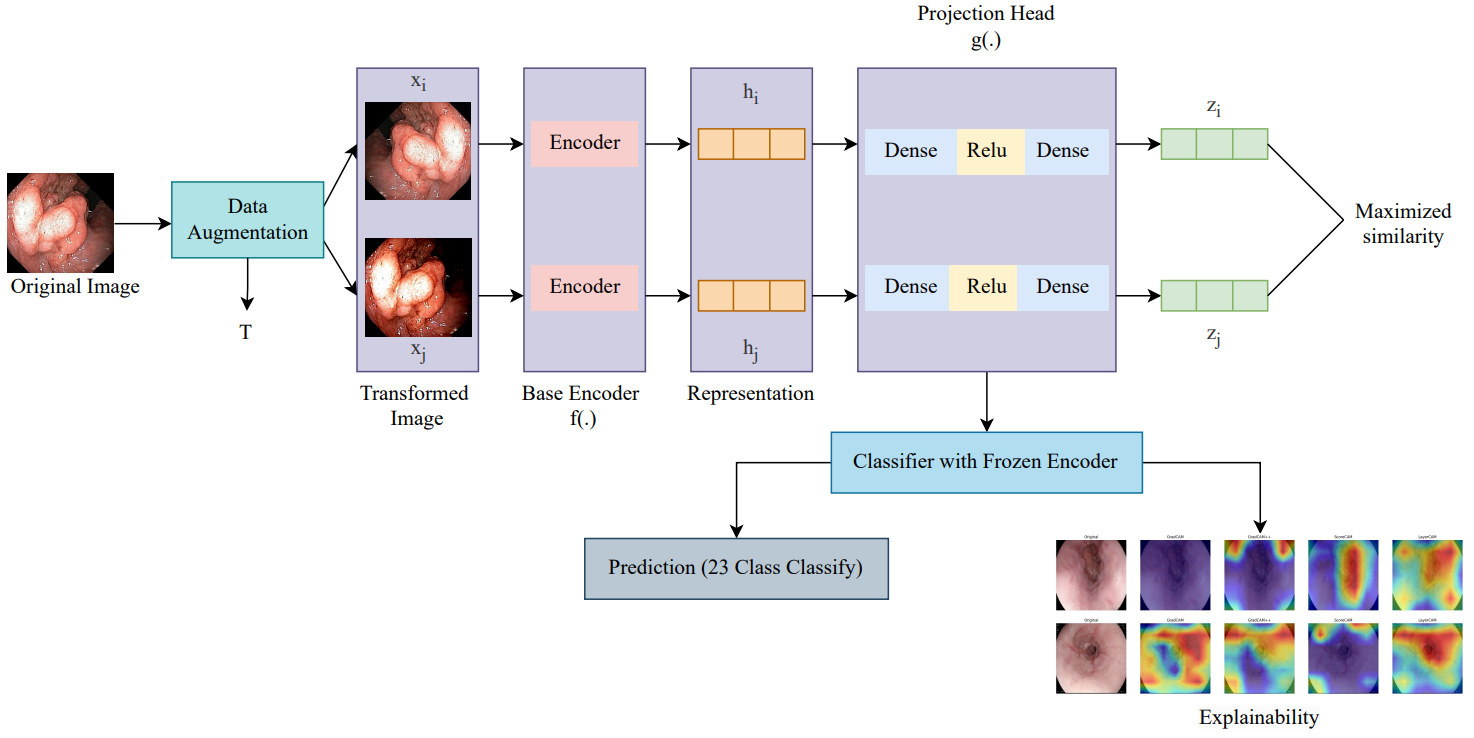
Contrastive Learning for API Aspect Analysis
G M Shahariar; Tahmid Hasan; Anindya Iqbal; Gias Uddin.
ASE 2023
TL;DR: We present a novel approach - CLAA - for API aspect detection in API reviews that utilizes transformer models trained with a supervised contrastive loss objective function.
Explainable Contrastive and Cost-Sensitive Learning for Cervical Cancer Classification
Ashfiqun Mustari; Rushmia Ahmed; Afsara Tasnim; Jakia Sultana Juthi; G M Shahariar.
ICCIT 2023
TL;DR: We apply the concept of supervised contrastive learning so that the models learn to extract more discriminative and representative features and enhance the classification accuracy.
Rank Your Summaries: Enhancing Bengali Text Summarization via Ranking-based Approach
G M Shahariar*; Tonmoy Talukder*; Rafin Alam Khan Sotez; Md. Tanvir Rouf Shawon. (* equal contribution )
BIM 2023
TL;DR: We introduce a graph based approach to rank the candidate summaries generated by multiple pre-trained transformer models, then select the most suitable one based on its high ranking score.
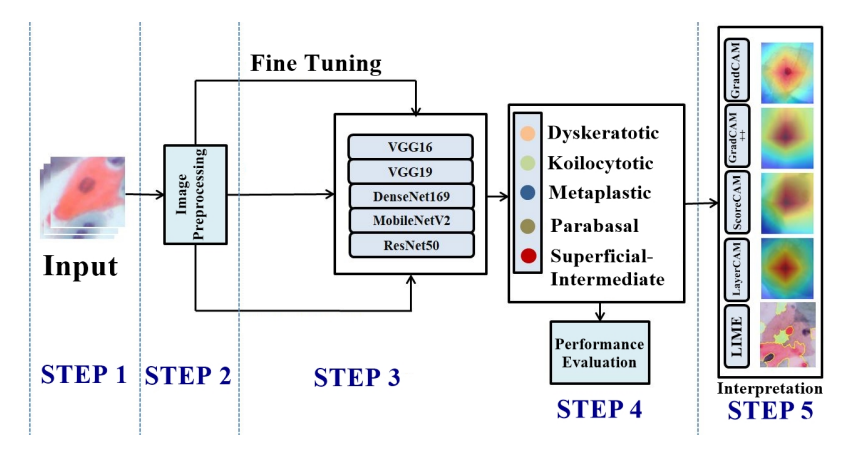
Gastrointestinal Disease Classification through Explainable and Cost-Sensitive Deep Neural Networks with Supervised Contrastive Learning
Dibya Nath; G M Shahariar.
Machine Learning for Healthcare Informatics 2023
TL;DR: We propose cost-sensitive pre-trained convolutional neural network (CNN) architectures fine-tuned using supervised contrastive learning objective for diagnosing gastrointestinal diseases on 23 distinct classes.
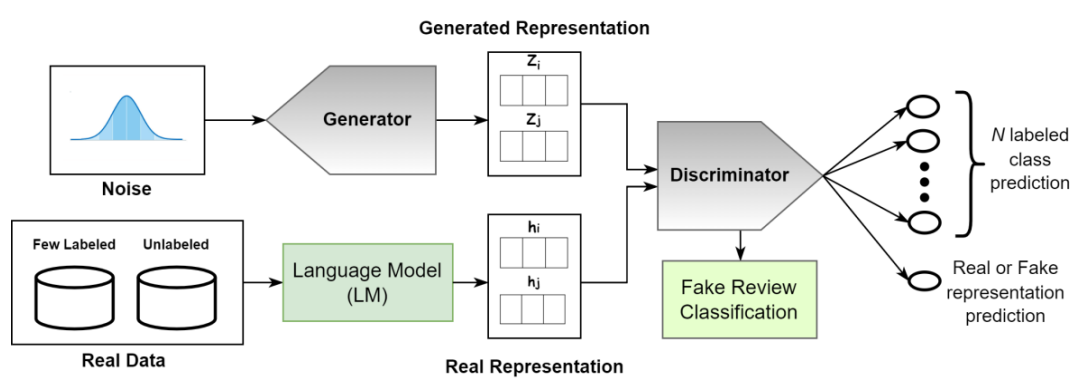
Bengali Fake Review Detection using Semi-supervised Generative Adversarial Networks
Md. Tanvir Rouf Shawon*; G M Shahariar*; Faisal Muhammad Shah; Mohammad Shafiul Alam; Md. Shahriar Mahbub. (* equal contribution )
ICNLP 2023
TL;DR: We propose a semisupervised generative adversarial network architecture with five pretrained language models to identify Bangla fake review texts.
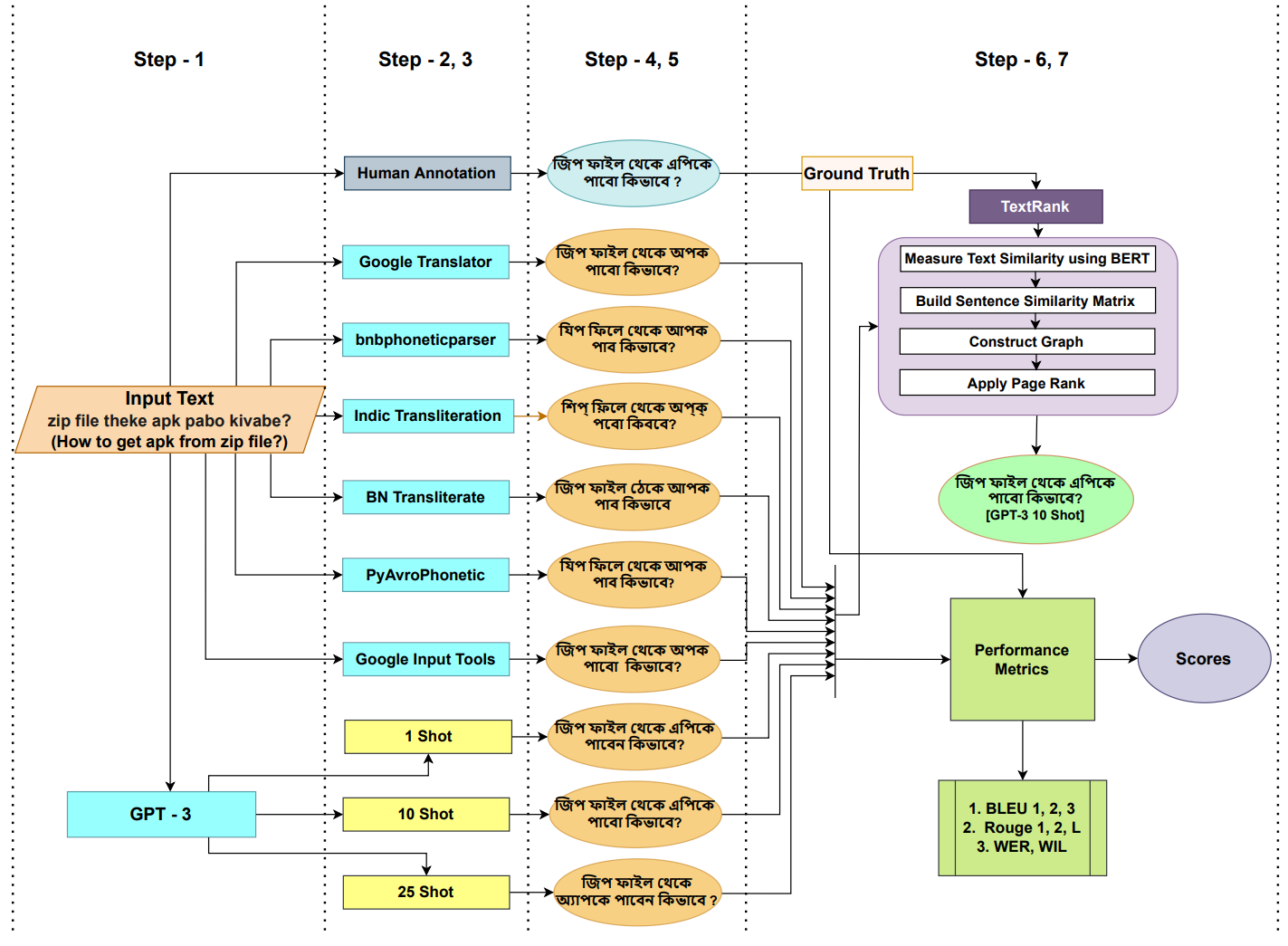
Automatic Back Transliteration of Romanized Bengali (Banglish) to Bengali
G M Shahariar; Md. Tanvir Rouf Shawon; Anik Hassan Nibir; Md. Zabed Miandad; Nibir Chandra Mandal.
Iran Journal of Computer Science 2023
TL;DR: We introduce an unique pipeline to automatically back transliterate from Romanized Bengali to Bengali using nine back transliteration open source tools, which are distinct from the current grapheme and phoneme based techniques.
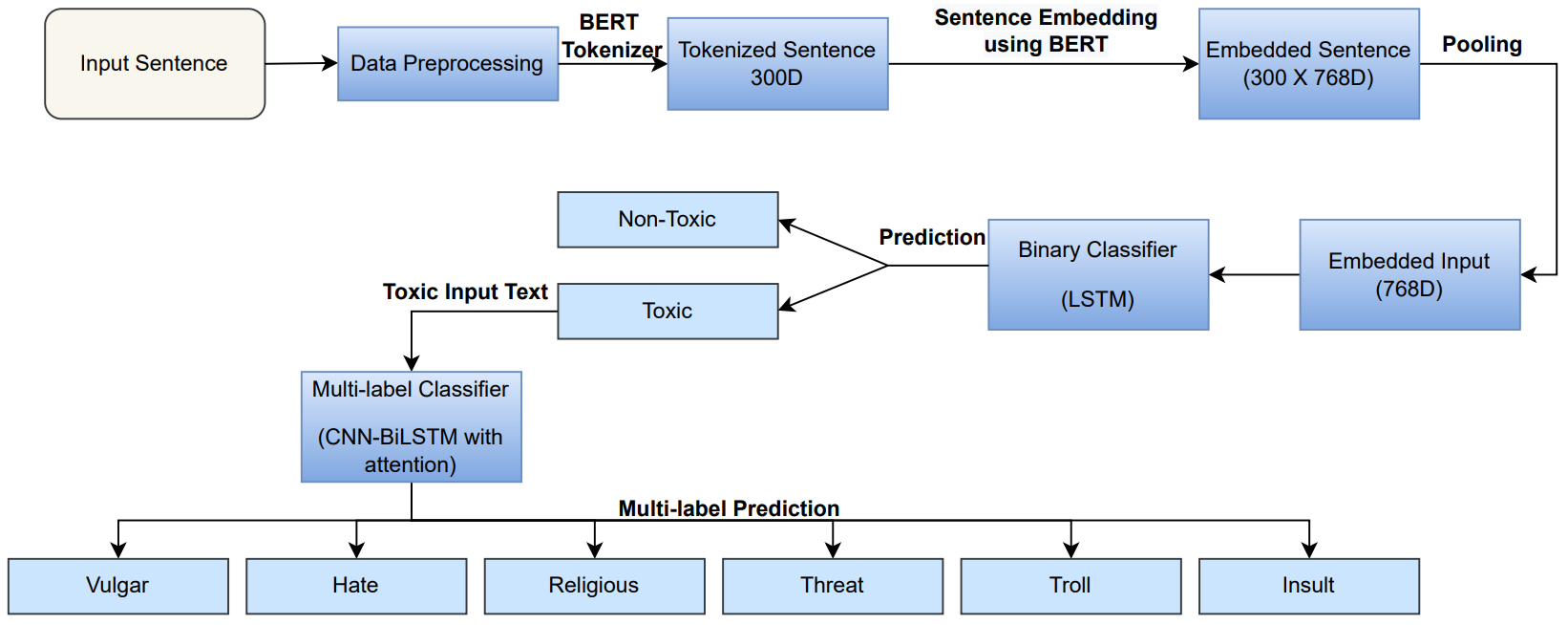
Interpretable Multi Labeled Bengali Toxic Comments Classification using Deep Learning
Tanveer Ahmed Belal; G M Shahariar; Hasanul Kabir.
ECCE 2023 Best Paper
TL;DR: We propose a pipeline where we first identify whether a comment is toxic or non-toxic by using a binary classification model, and if identified as toxic, we then employ a multi-label classifier to categorize the toxicity type.
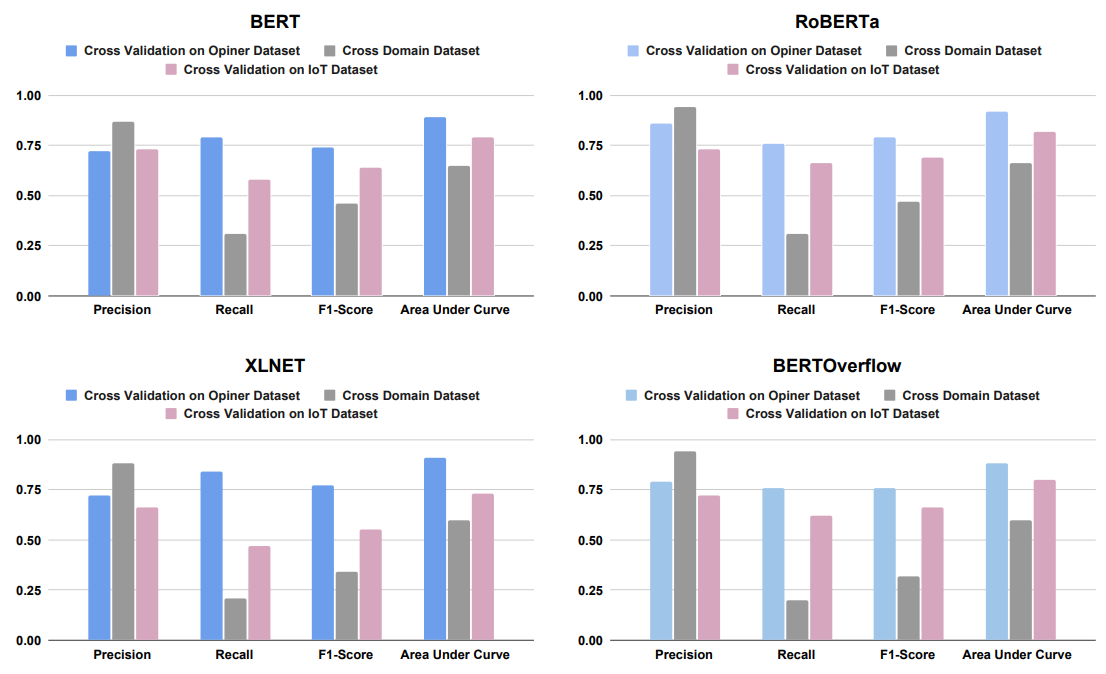
Effectiveness of Transformer Models on IoT Security Detection in StackOverflow Discussions
Nibir Chandra Mandal; G M Shahariar; Md. Tanvir Rouf Shawon.
ICICTD 2023
TL;DR: We employ multiple transformer models to automatically detect IoT security discussions on StackOverflow. Through rigorous investigations, we found that IoT security discussions are different and more complex than traditional.
2022
Can Transformer Models Effectively Detect Software Aspects in StackOverflow Discussion?
Nibir Chandra Mandal; Tashreef Muhammad; G M Shahariar.
MIET 2022
TL;DR: We conduct a thorough performance comparison and discovered that transformer models completely fail to understand some software aspects in stackoverflow discussions.
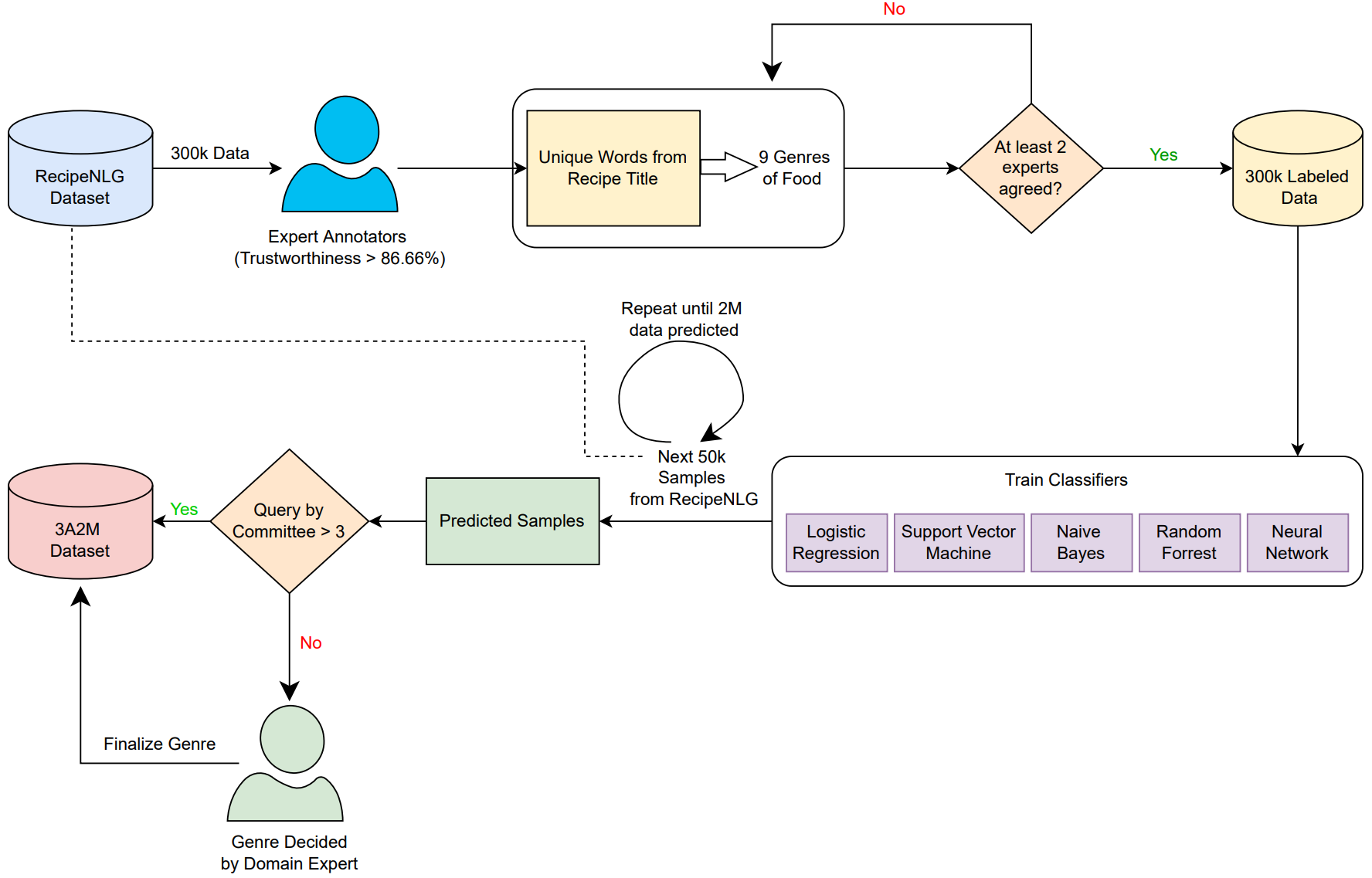
Assorted, Archetypal and Annotated Two Million (3A2M) Cooking Recipes Dataset based on Active Learning
Nazmus Sakib; G M Shahariar; Md. Mohsinul Kabir; Md. Kamrul Hasan; Hasan Mahmud.
MIET 2022
TL;DR: We apply active learning and ensemble-based techniques to semi-automate the annotation process of 2 million culinary data using Human-in-the-loop approach.
2019
Spam Review Detection Using Deep Learning
G M Shahariar; Swapnil Biswas; Faiza Omar; Faisal Muhammad Shah; Samiha Binte Hassan.
IEMCON 2019
TL;DR: We propose a deep learning framework to detect spam reviews.